After you design and partition your database schema (Chapter 4, Designing the Database Schema), and after you design the necessary stored procedures (Chapter 5, Designing Stored Procedures to Access the Database), you are ready to write the client application logic. The client code contains all the business-specific logic required for the application, including business rule validation and keeping track of constraints such as proper data ranges for arguments entered in stored procedure calls.
The three steps to using VoltDB from a client application are:
Creating a connection to the database
Calling stored procedures
Closing the client connection
The following sections explain how to perform these functions using the latest VoltDB Java client interface, known as
Client2. (See VoltDB Java Client
API.) The VoltDB Java Client is a thread-safe class library that provides runtime access to VoltDB databases and
functions.
It is possible to call VoltDB stored procedures from programming languages other than Java. However, reading this chapter is still recommended to understand the process for invoking and interpreting the results of a VoltDB stored procedure. See Chapter 8, Using VoltDB with Other Programming Languages for more information about using VoltDB from client applications written in other languages.
Client2 uses modern Java programming techniques and smarter defaults to provide a structured and extensible interface, including:
A "builder" pattern for the Client2Config, with individual methods that can be chained to set configuration options.
No mandatory settings, all attributes have default values.
Smarter default behavior to simplify application development.
Individually configured notifications, set as callbacks on the configuration object, that let the application decide which events it wants to be notified about and how.
Use of Java CompletableFutures to handle asynchronous procedure calls, giving the application developer more structured and precise handling of invocation events.
The first task for the calling program is to create a connection to the VoltDB database. You do this with the following steps:
Client2 client = null;
Client2Config config = null;
try {
config = new Client2Config().username("advent").password("xyzzy"); 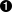 client = ClientFactory.createClient(config);
client = ClientFactory.createClient(config); 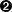 client.connectSync("myserver.xyz.net");
client.connectSync("myserver.xyz.net");  } catch (java.io.IOException ex) {
ex.printStackTrace();
System.exit(-1);
}
} catch (java.io.IOException ex) {
ex.printStackTrace();
System.exit(-1);
}
| Define the configuration for your connections. The |
| Create an instance of the VoltDB |
| Call the client.connectSync("myserver.xyz.net",21211);If security is enabled, and the username and password in the |
When you are done with the connection, you should make sure your application calls the close()
method to clean up any memory allocated for the connections. See Section 6.5, “Closing the Connection”.
A call to connectSync() sets up a connection to a single node in the database cluster before it
returns. The VoltDB client software (by default) then automatically establishes connections to all available cluster
nodes.
This automatic management of connections has these major benefits:
Multiple connections distribute the stored procedure requests around the cluster, avoiding a bottleneck where all requests are queued through a single host. This is particularly important when using asynchronous procedure calls or multiple clients.
For Java applications, the VoltDB Java client library uses client affinity. That is, the client knows which server to send each request to based on the partitioning, thereby eliminating unnecessary network hops.
Finally, if a server fails for any reason, when using K-safety the client can continue to submit requests through connections to the remaining nodes. This avoids a single point of failure between client and database cluster. See Chapter 11, Availability for more.
The client will automatically reconnect whenever the topology changes. That is, if a server fails and then rejoins the cluster, or new nodes are added to the cluster, the client will automatically create connections to the newly available servers.
You can specify more than one hostname or IP address in the connectSync call. The VoltDB client
software will then connect to the first available host in the list and then return to your application code. From that
point, the automatic management of connections will take over. The advantage of specifying more than one host is that it
builds in some resilency against temporary failure of some hosts. The connectSync() call will only fail
in the case that all of the given hosts are unavailable.
For example, the following Java code creates the client object specifying three alternative nodes for the initial connection to the cluster. In this case, security is not enabled, so username and password are not needed:
try {
client = ClientFactory.createClient(new Client2Config());
client.connectSync("server1.xyz.net,server2.xyz.net,server3.xyz.net");
} catch (java.io.IOException ex) {
ex.printStackTrace();
System.exit(-1);
}