The following sections provide step-by-step instructions for setting up and running passive replication between two VoltDB clusters. The steps include:
Specifying what tables to replicate in the schema
Configuring the master and replica root directories for DR
Starting the databases
Loading the schema
The remaining sections discuss other aspects of managing passive DR, including:
Stopping database replication
Promoting the replica database
Using the replica for read-only transactions
First, you must identify which tables you wish to copy from the master to the replica. Only the selected tables are copied. You identify the tables in both the master and the replica database schema with the DR TABLE statement, For example, the following statements identify two tables to be replicated, the Customers and Orders tables:
CREATE TABLE customers (
customerID INTEGER NOT NULL,
firstname VARCHAR(128),
lastname VARCHAR(128)
);
CREATE TABLE orders (
orderID INTEGER NOT NULL,
customerID INTEGER NOT NULL,
placed TIMESTAMP
);
DR TABLE customers;
DR TABLE orders;You can identify any regular table, whether partitioned or not, as a DR table, as long as the table is empty. That is, the table must have no data in it when you issue the DR TABLE statement.
The important point to remember is that the schema for both databases must contain matching table definitions for any tables identified as DR tables, including the associated DR TABLE declarations. Although it is easiest to have the master and replica databases use the exact same schema, that is not necessary. The replica can have a subset or superset of the tables in the master, as long as it contains matching definitions for all of the DR tables. The replica schema can even contain additional objects not in the master schema, such as additional views. Which can be useful when using the replica for read-only or reporting workloads, just as long as the DR tables match.
The next step is to properly configure the master and replica clusters. The two database clusters can have different physical configurations (that is, different numbers of nodes, different sites per host, or a different K factor). Identical cluster configurations guarantee the most efficient replication, because the replica does not need to repartition the incoming binary logs. Differing configurations, on the other hand, may incrementally increase the time needed to apply the binary logs.
Before you start the databases, you must initialize the root directories for both clusters with the appropriate DR
attributes. You enable DR in the configuration file using the <dr> element,
including a unique cluster ID for each database cluster and that cluster's role. The ID is a number between 0 and 127
which VoltDB uses to uniquely identify each cluster as part of the DR process. The role is either
master or replica.
For example, you could assign ID=1 for the master cluster and ID=2 for the replica. On the replica, you must also
include a <connection> sub-element that points to the master database. For
example:
<dr id="1" role="master"/>
<dr id="2" role="replica"> <connection source="MasterSvrA,MasterSvrB" /> </dr>
The next step is to start the databases. You start the master database as normal with the voltdb start command. If you are creating a new database, you can then load the schema, including the necessary DR TABLE statements. Or you can restore a previous database instance if desired. Once the master database starts, it is ready and can interact with client applications.
For the replica database, you use the voltdb start command to start a new, empty database. Once the database is running, you can execute DDL statements to load the database schema, but you cannot perform any data manipulation queries such as INSERT, UPDATE, or DELETE because the replica is in read-only mode.
The source attribute of the <connection> tag in the replica configuration file identifies the hostname or IP address
(and optionally port number) of one or more servers in the master cluster. You can specify multiple servers so that DR can
start even if one of the listed servers on the master cluster is currently down.
It is usually convenient to specify the connection information when initializing the database root directory. But this property can be changed after the database is running, in case you do not know the address of the master cluster nodes before starting. (Note, however, that the cluster ID cannot be changed once the database starts.)
As soon as the replica database starts with DR enabled, it will attempt to contact the master database to start replication. The replica will issue warnings that the schema does not match, since the replica does not have any schema defined yet. This is normal. The replica will periodically contact the master until the schema for DR objects on the two databases match. This gives you time to load a matching schema.
As soon as the replica database has started, you can load the appropriate schema. Loading the same schema as the master database is the easiest and recommended approach. The key point is that once a matching schema is loaded, replication will begin automatically.
When replication starts, the following actions occur:
The replica and master databases verify that the DR tables match on the two clusters.
If data already exists in the DR tables on the master, the master sends a snapshot of the current contents to the replica where it is restored into the appropriate tables.
Once the snapshot, if any, is restored, the master starts sending binary logs of changes to the DR tables to the replica.
If any errors occur during the snapshot transmission, replication stops and must be restarted from the beginning. However, once the third step is reached, replication proceeds independently for each unique partition and, in a K safe environment, the DR process becomes durable across node failures and rejoins and other non-fatal events.
If either the master or the replica database crashes and needs to restart, it is possible to restart DR where it left off, assuming the databases are using command logging for recovery. If the master fails, you simply use the voltdb start command to restart the master database. The replica will wait for the master to recover. The master will then replay any DR logs on disk and resume DR where it left off.
If the replica fails, the master will queue the DR logs to disk waiting for the replica to return. If you use the voltdb start command on the replica cluster, the replica will perform the following actions:
Restart the replica database, restoring both the schema and the data, and placing the database in read-only mode.
Contact the master cluster and attempt to re-establish DR.
If both clusters agree on where (that is, what transaction), DR was interrupted, DR will resume from that point, starting with the DR logs that the master database has queued in the interim.
If the clusters do not agree on where DR stopped during step #3, the replica database will generate an error and stop replication. For example, if you recover from an asynchronous command log where the last few DR logs were ACKed to the master but not written to the command log, the master and the replica will be in different states when the replica recovers.
If this occurs, you must restart DR from the beginning, by re-initializing the replica root directory (with the --force flag), restarting the database, and then reloading a compatible schema. Similarly, if you are not using command logging, you cannot recover the replica database and must start DR from scratch.
If, for any reason, you wish to stop replication of a database, there are two ways to do this: you can stop sending data from the master or you can "promote" the replica to stop it from receiving data. Since the individual partitions are replicating data independently, if possible you want to make sure all pending transfers are completed before turning off replication.
So, under the best circumstances, you should perform the following steps to stop replication:
Stop write transactions on the master database by putting it in admin mode using the voltadmin pause command.
Wait for all pending DR log transfers to be completed.
Reset DR on the master cluster using the voltadmin dr reset command.
Depending on your goals, either shut down the replica or promote it to a fully-functional database as described in Section 11.2.5.3, “Promoting the Replica When the Master Becomes Unavailable”.
If the replica becomes unavailable and is not going to be recovered or restarted, you should consider stopping DR on the master database, to avoid consuming unnecessary disk space.
The DR process is resilient against network glitches and node or cluster failures. This durability is achieved by the master database continually queueing DR logs in memory and — if too much memory is required — to disk while it waits for the replica to ACK the last message. This way, when the network interruption or other delay is cleared, the DR process can pick up where it left off. However, the master database has no way to distinguish a temporary network failure from an actual stoppage of DR on the replica.
Therefore, if the replica stops unexpectedly, it is a good idea to restart the replica and re-initiate DR as soon as convenient. Or, if you are not going to restart DR, you should reset DR on the master to cancel the queuing of DR logs and to delete any pending logs. To reset the DR process on the master database, use the voltadmin dr reset command. For example:
$ voltadmin dr reset --host=serverA
Of course, if you do intend to recover and restart DR on the replica, you do not want to reset DR on the master. Resetting DR on the master will delete any queued DR logs and make restarting replication where it left off impossible and force you to start DR over from the beginning.
If unforeseen events occur that make the master database unreachable, database replication lets you replace the master with the replica and restore normal business operations with as little downtime as possible. You switch the replica from read-only to a fully functional database by promoting it. To do this, perform the following steps:
Make sure the master is actually unreachable, because you do not want two live copies of the same database. If it is reachable but not functioning properly, be sure to pause or shut down the master database.
Promote the replica to a read/write mode using the voltadmin promote command.
Redirect the client applications to the newly promoted database.
Figure 11.4, “Promoting the Replica” illustrates how database replication reduces the risk of major disasters by allowing the replica to replace the master if the master becomes unavailable.
Once the master is offline and the replica is promoted, the data is no longer being replicated. As soon as normal business operations have been re-established, it is a good idea to also re-establish replication. This can be done using any of the following options:
If the original master database hardware can be restarted, take a snapshot of the current database (that is, the original replica), restore the snapshot on the original master and redirect client traffic back to the original. Replication can then be restarted using the original configuration.
An alternative, if the original database hardware can be restarted but you do not want to (or need to) redirect the clients away from the current database, is to use the original master hardware to create a replica of the newly promoted cluster — essentially switching the roles of the master and replica databases — as described in Section 11.2.5.4, “Reversing the Master/Replica Roles”.
If the original master hardware cannot be recovered effectively, create a new database cluster in a third location to use as a replica of the current database.
If the master database becomes unreachable for whatever reason (such as catastrophic system or network failure) it may not be possible to turn off DR in an orderly fashion. In this case, you may choose to “turn on” the replica as a fully active (writable) database to replace the master. To do this, you use the voltadmin promote command. When you promote the replica database, it exits read-only mode and becomes a fully operational VoltDB database. For example, the following Linux shell command uses voltadmin to promote the replica node serverB:
$ voltadmin promote --host=serverB
If you do promote the replica and start using it as the primary database, you will likely want to establish a new
replica as soon as possible to return to the original production configuration and level of durability. You can do this
by creating a new replica cluster and connecting to the promoted database as described in Section 11.2.3, “Starting the Clusters”. Or, if the master database can be restarted, you can reuse that cluster as the new
replica, by modifying the configuration file to change the DR role from master to
replica, and add the necessary <connection> element,
re-initializing the database root directory, and then starting the new database cluster with the voltdb
start command.
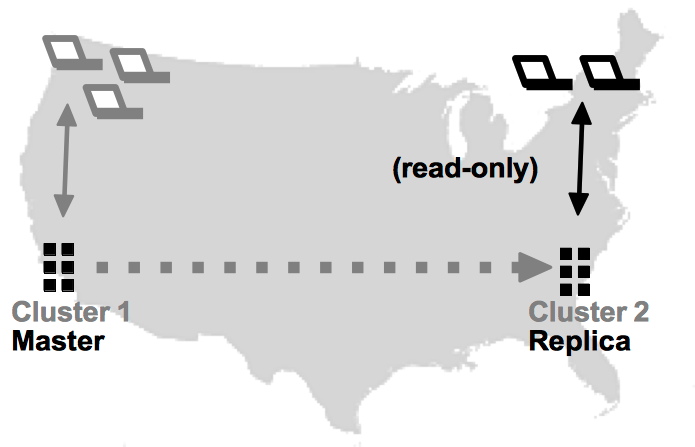
While database replication is occurring, the only changes to the replica database come from the binary logs. Client applications can connect to the replica and use it for read-only transactions, including read-only ad hoc queries and system procedures. However, any attempt to perform a write transaction from a client application returns an error.
There will always be some delay between a transaction completing on the master and its results being applied on the replica. However, for read operations that do not require real-time accuracy (such as reporting), the replica can provide a useful source for offloading certain less-frequent, read-only transactions from the master.