VoltDB achieves scalability by creating a tightly bound network of servers that distribute both data and processing. When you configure and manage your own server hardware, you can ensure that the cluster resides on a single network switch, guaranteeing the best network connection between nodes and reducing the possibility of network faults interfering with communication.
However, there are situations where this is not the case. For example, if you run VoltDB "in the cloud", you may not control or even know what is the physical configuration of your cluster.
The danger is that a network fault — between switches, for example — can interrupt communication between nodes in the cluster. The server nodes continue to run, and may even be able to communicate with others nodes on their side of the fault, but cannot "see" the rest of the cluster. In fact, both halves of the cluster think that the other half has failed. This condition is known as a network partition.
When you run a VoltDB cluster without availability (in other words, no K-safety) the danger of a network partition is simple: loss of the database. Any node failure makes the cluster incomplete and the database will stop, You will need to reestablish network communications, restart VoltDB, and restore the database from the last snapshot.
However, if you are running a cluster with K-safety, it is possible that when a network partition occurs, the two separate segments of the cluster might have enough partitions each to continue running, each thinking the other group of nodes has failed.
For example, if you have a 3 node cluster with 2 sites per node, and a K-safety value of 2, each node is a separate, self-sustaining copy of the database, as shown in Figure 11.2, “Network Partition”. If a network partition separates nodes A and B from node C, each segment has sufficient partitions remaining to sustain the database. Nodes A and B think node C has failed; node C thinks that nodes A and B have failed.
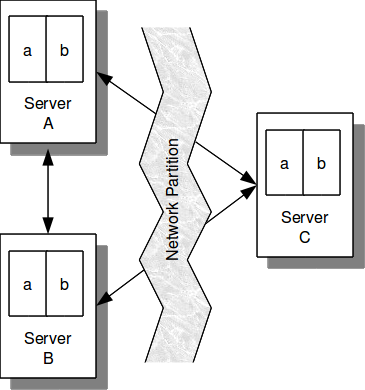
The problem is that you never want two separate copies of the database continuing to operate and accepting requests thinking they are the only viable copy. If the cluster is physically on a single network switch, the threat of a network partition is reduced. But if the cluster is on multiple switches, the risk increases significantly and must be accounted for.
VoltDB provides a mechanism for guaranteeing that a network partition does not accidentally create two separate copies of the database. The feature is called network fault protection. When a fault is detected (either due to a network fault or one or more servers failing), any viable segment of the cluster will perform the following steps:
Determine what nodes are missing
Determine if the missing nodes are also a viable self-sustained cluster. If so...
Determine which segment is the larger segment (that is, contains more nodes).
If the current segment is larger, continue to operate assuming the nodes in the smaller segment have failed.
If the other segment is larger, shutdown to avoid creating two separate copies of the database.
For example, in the case shown in Figure 11.2, “Network Partition”, if a network partition separates nodes A and B from C, the larger segment (nodes A and B) will continue to run and node C will shutdown (as shown in Figure 11.3, “Network Fault Protection in Action”).
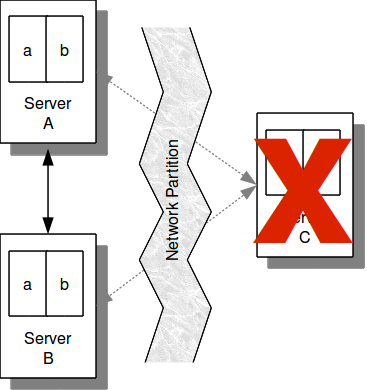
If a network partition creates two viable segments of the same size (for example, if a four node cluster is split into two two-node segments), a special case is invoked where one segment is uniquely chosen to continue, based on the internal numbering of the host nodes. Thereby ensuring that only one viable segment of the partitioned database continues.
Network fault protection is a very valuable tool when running VoltDB clusters in a distributed or uncontrolled environment where network partitions may occur. The one downside is that there is no way to differentiate between network partitions and actual node failures. In the case where no network partition occurs but a large number of nodes actually fail, the remaining nodes may believe they are the smaller segment. In this case, the remaining nodes will shut themselves down to avoid partitioning.
For example, in the previous case shown in Figure 11.3, “Network Fault Protection in Action”, if rather than a network partition, nodes A and B fail, node C is the only node still running. Although node C is viable and could continue because the database was configured with K-safety set to 2, with fault protection node C will shut itself down to avoid a partition. For higher values of K-safety, the calculation of which segment stays up becomes more complex since the network topology can change dynamically if network partitions happen in sequence. However, the principle remains the same: to ensure that only one segment continues to run and it is possible all segments will shut down if there is ambiguity about which segments may still be viable. Specifically, if a node loses contact with all other nodes, even if it would normally be the surviving node, if it was previously part of a cluster with three or more nodes, it will shut itself down to avoid a potential network partition.
In the worst case, if half the nodes of a cluster fail, the remaining nodes may actually shut themselves down under the special provisions for a network partition that splits a cluster into two equal parts. For example, consider the situation where a two node cluster with a k-safety value of one has network partition detection enabled. If one of the nodes fails (half the cluster), there is only a 50/50 chance the remaining node is the "blessed" node chosen to continue under these conditions. If the remaining node is not the chosen node, it will shut itself down to avoid a conflict, taking the database out of service in the process.
Because this situation — a 50/50 split — could result in either a network partition or a viable cluster shutting down, VoltDB recommends always using clusters with an odd number of nodes when creating small clusters. By using an odd number of servers, you avoid even the possibility of a 50/50 split, whether caused by partitioning or node failures. For larger clusters, the chance of losing exactly half the cluster is relatively small and so an even number of nodes (such as six, eight, or larger) is rarely a problem.