Active(N) database replication is designed to accommodate different workloads and will provide outstanding performance for most active database applications. However, the default settings may not meet the needs of all business use cases. There are a number of configuration options available to help you optimize replication to meet your specific needs. Before adjusting the configuration, you need to understand how the DR consumers and producers interoperate so you can understand what effect each option has on the flow of data between the clusters.
The following sections explain the XDCR workflow process and how to detect and resolve possible bottlenecks in runtime performance.
In an Active(N) environment, each unique partition within the cluster acts as both a DR producer and consumer. As a producer, the cluster sends the results of any transactions that modify the database content to the participating clusters. At the same time, as a consumer the cluster receives transaction results from the other clusters and applies them to its copy of the database. The producer and consumer operations are performed on a per partition basis, as shown in Figure 11.7, “The XDCR Producer/Consumer Workflow”.
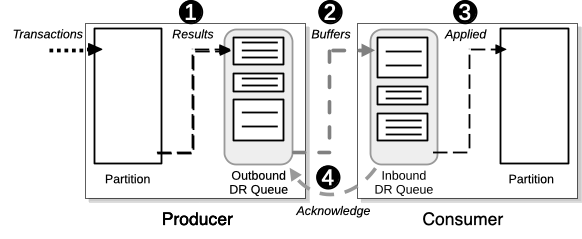
The workflow consists of four main steps:
| As transactions are processed on the producer cluster, results of transactions that alter the database contents are added as binary logs to buffers in the producer's outbound queue. |
| The buffers are then sent to the consumer cluster (or multiple consumers if there are three or more clusters in the quorum). When the consumer receives the buffers, they are added to the consumer's inbound queue. |
| The buffers are then processed in sequential order, applying the binary logs to the consumer's database contents. |
| Once a buffer is processed, acknowledgement is sent back to the producer cluster so it knows that the data has been successfully processed and the buffer can (once all consumer clusters acknowledge it) be deleted from the queue. |


The workflow is optimized to allow each component to operate independently, maximizing efficiency:
The size of transaction results vary dramatically — from tens of bytes to as much as 37 megabytes — depending on how many records are affected, the size of the records, etc. As a result, the number of transactions in any given buffer can also vary, as can the size of the buffer itself.
When the producer sends buffers it sends all of the available buffers not already acknowledged by the consumer.
On the receiving end, when the consumer receives buffers from the producer it places as many buffers as it can fit on the inbound queue. If the queue limit is too low to accommodate all of the buffers, the consumer simply drops the excess buffers. This means the producer will resend the dropped buffers in the next packet it sends, which causes some redundancy. However, the additional network bandwidth is usually a minimal cost to avoid any temporary delays in the consumer causing backups in the producer.
Even if a buffer is added to the inbound queue, it is possible the consumer does not have time to apply and acknowledge the transactions before the producer sends the next batch of buffers. When this happens, the same buffer may be sent twice. The consumer simply adds the duplicate buffer to the queue and when it comes time to apply it, recognizes that the buffer has already been applied, throws it away and moves on to the next buffer in the queue.
Under normal conditions, there will be occasional buffers discarded by the consumer and some sent multiple times from the producer. This is not a problem because the workflow accommodates the exceptions and allows each cluster to perform its functions at maximum speed. The producer periodically sending too many buffers or duplicate buffers does not result in any noticeable performance impact.
However, if there are continual or increasingly frequent buffers rejected or resent, the condition points to bottlenecks in the workflow that can result in delays in data replication. Volt provides metrics that help you detect and correct these situations. In particular, there are three statistics that help detect issues with XDCR:
Buffers ignored by the consumer — This is the number of excess buffers the consumer receives from the producer but cannot fit within the consumer's inbound queue. The value is returned in the IGNORED_BUFFERS column returned by the @Statistics DRCONSUMER selector.
Duplicate buffers dropped by the consumer — This is the number of duplicate buffers that are sent to the consumer, added to the queue, then discarded when it comes time to apply them since the associated transaction results have already been applied. The value is returned in the DUPLICATE_BUFFERS column returned by the @Statistics DRCONSUMER selector
Latency between the producer and the consumer — There are four columns available on the producer that provide information on the latency of DR transactions; that is, how long it takes for a transaction to be sent to the consumer, applied, and then acknowledged back to the producer. There is both a maximum and average value in milliseconds, measured both over the past minute and past five minutes. These DR_ROUNDTRIPTIME_* columns of the @Statistics DRPRODUCER selector can help you determine if there are delays in the workflow and, with the other statistics, where those delays may be.
These statistics are available from the @Statistics system procedure or from the corresponding Prometheus metrics, as described in the Volt Administrator's Guide. By tracking these statistics over time, you can detect potential issues in the replication workflow, as described in the following sections.
If the number of ignored buffers (IGNORED_BUFFERS) is high or steadily increasing, while the number of duplicate buffers remains low, it means that the maximum queue size for the consumer is not large enough to hold the amount of buffered DR transactions being sent by the producer(s). By increasing the maximum size you can provide the space needed to hold the volume of incoming buffers.
You specify the size in bytes[3] as part of the connection configuration, using the maxsize attribute
of the <consumerlimit> element. For example, the following configuration
doubles the consumer queue from the default of 50MB (52428800 bytes) to 100MB :
<dr id="1" role="xdcr">
<connection source="chicago,boston"/>
<consumerlimit maxize="104857600"/>
</dr>Of course, increasing the queue size can reduce the number of ignored buffers, but it also increases memory utilization across the cluster. By specifying the limit in bytes you can estimate how much of an increase that will be, since the total memory required for the consumer queues is approximately the size of the queue limit in bytes times the number of unique partitions on the cluster. The calculation is not exact because if there is any room in the queue when the consumer receives buffers from the producer, at least one buffer will be placed on the queue, even if that buffer extends the queue beyond its configured size. So be sure to allow some additional space for this overflow.
You can increase the consumer queue size on a running cluster using the voltadmin update command. After making the adjustment, be sure to measure the number of ignored buffers again to verify that the change has the desired effect and the count of ignored buffers has gone down.
If the duplicate buffer count (DUPLICATE_BUFFERS) is high, and especially if it is increasing over time, it means that the consumer cluster is not able to keep up processing the incoming buffers at the same rate they are being generated. There are several possible causes for this situation and the resolution depends on the cause.
First and foremost, check the ignore buffers to make sure the consumer queue is large enough to handle the incoming traffic.
Next, make sure the clusters are homogeneous; that is, they have the same physical configuration or at least the same number of unique partitions. If the clusters have a different partition count, the DR consumer will have to redistribute the transaction results it receives from the producer to the appropriate partitions within the consumer cluster, significantly increasing the time needed to apply the buffers. Heterogeneous clusters may have a significant impact on the latency of DR processing and are therefore not generally recommended for production use, except temporarily during elastic expansion or contraction.
If the cluster are homogeneous and have a suitably sized consumer queue, the next step is to check to see if undue latency is delaying the delivery of buffers to the inbound queue, in particular, look for network delays, as described in Section 11.5.2.3, “Too Much Latency Between Clusters”.
If no other causes can be found, check for conflicts on the consumer cluster itself that could delay DR processing. Issues to look for are:
Non-Volt processes competing for system resources,
Frequent or long-running multi-partition procedures on the consumer blocking the individual partitions from applying the inbound DR buffers
An imbalance in the workload across the XDCR clusters
The DR_ROUNDTRIPTIME_* columns returned by the @Statistics DRPRODUCER selector tell you how long it is taking for transactions to be sent from the producer to the consumer, be applied, and then acknowledged. If the consumer queue is too small or other activity on the server is delaying the processing of buffers in the DR consumer queue, this latency will be reflected in the round trip times reported by @Statistics, as well as in the IGNORED_BUFFERS and DUPLICATE_BUFFERS counts reported by the @Statistics DRCONSUMER selector.
However, if the consumer buffer is not overflowing and DR transaction results are being applied efficiently but the latency reported by the round trip time is still high, there are two other possible issues that need to be addressed. The first is to investigate whether the latency is due to slow or erratic network performance. You can use standard networking utilities such as ping to evaluate the network performance between the clusters.
The other situation that can result in unexpected latency in DR processing is if the volume of write transactions is so low or erratic, there is not enough traffic to actually fill the outbound buffers in a timely fashion. In this case the producer waits for additional transaction results to fill the buffer before adding it to the outbound queue. Eventually, even if no additional transactions arrive, the producer will submit whatever transaction results are waiting into a buffer and add them to the queue. However, the period between when a transaction is executed and when the buffer is finally submitted will result in increased latency. For workloads of this nature, there is a setting that helps reduce the latency between transaction execution and adding the results to the outbound queue and this is the DR flush interval.
The flush interval specifies a timeout period where, even if there are not enough results to fill a buffer, the
results are submitted to the queue. The flush interval defaults to one second, but if you have an low or erratic
workload you can specify a shorter flush interval using the <flushinterval>
element under <systemsettings> in the configuration file. For example, the
following configuration sets the flush interval for XDCR to half a second:
<systemsettings> <flushinterval dr="500"/> </systemsettings>
[3] It is also possible to specify the consumer queue size in number of buffers. However, that is not recommended since buffers can vary dramatically in size. Specifying the queue size in bytes rather than buffers gives you control over how much memory may be consumed at run time.