Earlier chapters discuss features of VoltDB as a standalone component of your business application. But like most technologies, VoltDB is often used within a diverse and heterogeneous computing ecosystem where it needs to "play well" with other services This chapter describes features of VoltDB that help integrate it with other databases, systems, and applications to simplify, automate, and speed up your business processes.
Just as VoltDB as a database aims to provide the optimal transaction throughput, VoltDB as a data service aims to efficiently and reliably transfer data to and from other services. Of course, you can always write custom code to integrate VoltDB into your application environment, calling stored procedures to move data in and out of the database. However, the VoltDB feature set simplifies and automates the process of streaming data into, out of, and through VoltDB allowing your application to focus on the important work of analyzing, processing, and modifying the data in flight through secure, reliable transactions. To make this possible, VoltDB introduces four key concepts:
Streams
Import
Export
Migration
Streams operate much like regular database tables. You define them with a CREATE statement like tables, they consist of columns and you insert data into streams the same way you insert data into tables using the INSERT statement. You can define views that aggregate the data as it passes through the stream. Interactions with streams within a stored procedure are transactional just like tables. The only difference is a stream does not store any data in the database. This allows you to use all the consistency and reliability of a transactional database and the familiar syntax of SQL to manage data "in flight" without necessarily having to save it to persistent storage. Of course, since there is no storage associated with streams, they are for INSERT only. Any attempt to SELECT, UPDATE, or DELETE data from a stream results in an error.
Import automates the process of pulling data from external sources and inserting it into the database workflow through the same stored procedures your applications use. The import connectors are declared as part of the database configuration and stop and start with the database. The key point being that the database manages the entire import process and ensures the durability of the data while it is within VoltDB. Alternately, you can use one of the VoltDB data loading utilities to push data into the VoltDB database from a variety of sources.
Export automates the reverse process from import: it manages copying any data written to an export table or stream and sending it to the associated external target, whether it be a file, a service such as Kafka, or another database. The export targets are defined in the database configuration file, while the connection of a table or stream to it specific export target is done in the data definition language (DDL) CREATE statement using the EXPORT TO TARGET clause.
Migration is a special case of export where export is more fully integrated into the business workflow. When you define a table with the MIGRATE TO TARGET clause instead of EXPORT TO TARGET, data is not deleted from the VoltDB table until it is successfully written to the associated target. You trigger a migration of data using an explicit MIGRATE statement or you can declare the table with USING TTL to schedule the migration based on a timestamp within the data records and an expiration time defined as the TTL value.
How you configure these features depends on your specific business goals. The bulk of this chapter describes how to declare and configure import, export and migration in detail. The next two sections provide an overview of how data streaming works and how to use these features to perform common business activities.
Import associates incoming data with a stored procedure that determines what is done with the data. Export associates a database object (a table or stream) with an external target, where the external target determines how the exported data is handled. But in both cases the handling of streamed data follows three key principles:
Interaction with the VoltDB database is transactional, providing the same ACID guarantees as all other transactions.
Interaction with the external system occurs as a separate asynchronous process, avoiding any negative impact on the latency of ongoing transactions in the VoltDB database.
The VoltDB server takes care of starting and stopping the import and export subsystems when the database starts and stops. The server also takes responsibility for managing streaming data "in flight" — ensuring that no data is lost once it enters the subsystem and before it reaches its final destination.
VoltDB database achieves these goals is by having separate export and import connectors handle the data as it passes from one system to the next as shown in Figure 15.1, “Overview of Data Streaming”.
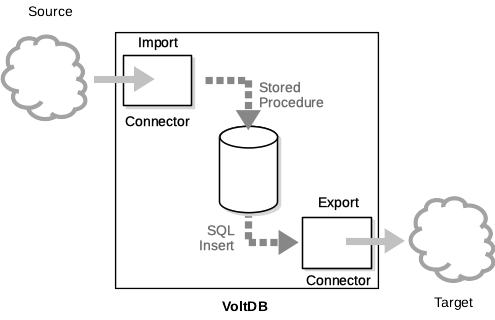
Which streaming features you use depend on your business requirements. The key point is that orchestrating multiple disparate systems is complex and error prone and the VoltDB streaming services free you from these complexities by ensuring that all operations start and stop automatically as part of the server process, the data in flight is made durable across database sessions, and that all data is delivered at least once or retained until delivery is possible.
The following sections provide an overview of each service. Later sections describe the services and built-in connectors in more detail. You can also define your own custom import and export connectors, as described in the VoltDB Guide to Performance and Customization.
To import data into VoltDB from an external system you have two options: you can use one of the standard VoltDB data loading utilities (such as csvloader) or you can define an import connector in the database configuration file that associates the external source with a stored procedure. The data loading utilities are standalone external applications that push data into the VoltDB database. VoltDB import connectors use a pull model. In other words, the connector periodically checks the data source to determine if new content is available. If so, the connector retrieves the data and passes it to the stored procedure where it can analyze the data, validate it, manipulate it, insert it into the database, or even pass it along to an export stream; whatever your application needs.
The creation of the import connector is done using the <configuration> tag within the <import> ... </import> element of the configuration file. The attributes of the <configuration> tag specify the type of import connector to use (Kafka, Kinesis, or custom) and, optionally, the input format (CSV by default). The <property> tags within the configuration specify the actual data source, the stored procedure to use as a destination, and any other connector-specific attributes you wish to set.
For example, to process data from a Kafka topic, the connector definition must specify the type (kafka), the addresses of one or more Kafka brokers as the source, the name of the topic (or topics), and the stored procedure to process the data. If the data does not need additional processing, you can use the default stored procedure that VoltDB generates for each table to insert the data directly into the database. The following configuration reads the Kafka topics nyse and nasdaq in CSV format and inserts records into the stocks table using the default insert procedure:
<import>
<configuration type="kafka" format="csv">
<property name="brokers">kafkasvr1:9092,kafkasvr2:9092</property>
<property name="topics">nyse,nasdaq</property>
<property name="procedure">STOCKS.insert</property>
</configuration>
</import>Having the import connectors defined in the configuration file lets VoltDB manage the entire import process, from starting and stopping the connectors to making sure the specified stored procedure exists, fetching the data in batches and ensuring nothing is lost in transit. You can even add, delete, or modify the connector definitions on the fly by updating the database configuration file while the database is running.
VoltDB provides built-in import connectors for Kafka and Kinesis. Section 15.4, “VoltDB Import Connectors” describes these built-in connectors and the required and optional properties for each. Section 15.5, “VoltDB Import Formatters” provides additional information about the input formatters that prepare the incoming data for the stored procedure.
To export data from VoltDB to an external system you define a database table or stream as the export source by including the EXPORT TO TARGET clause in the DDL definition and associating that data source with a logical target name. For example, to associate the stream alerts with a target called systemlog, you would declare a stream like so:
CREATE STREAM alerts
EXPORT TO TARGET systemlog
( {column-definition} [,...] );For tables, you can also specify when data is queued for export. By default, data inserted into export tables with the INSERT statement (or UPSERT that results in a new record being inserted) is queued to the target, similar to streams. However, you can customize the export to write on any combination of data manipulation language (DML) statements, using the ON clause. For example, to include updates into the export steam, the CREATE TABLE statement might look like this:
CREATE TABLE orders
EXPORT TO TARGET orderprocessing ON INSERT, UPDATE
( {column-definition} [,...] );As soon as you declare a stream or table as exporting to a target, any data written to that source (or in the case of tables, the export actions you specified in the CREATE TABLE statement) is queued for the export stream. You associate the named target with a specific connector and external system in the <export> ... </export> section of the database configuration file. Note that you can define the target either before or after declaring the source, and you can add, remove, or modify the export configuration at any time before or after the database is started.
In the configuration file you define the export connector using the <configuration> element, identifying the target name and type of connector to use. Within the <configuration> element you then identify the specific external target to use and any necessary connector-specific attributes in <property> tags. For example, to write export data to files locally on the database servers, you use the file connector and specify attributes such as the file prefix, location, and roll-over frequency as properties:
<export>
<configuration target="systemlog" type="file">
<property name="type">csv</property>
<property name="nonce">syslog</property>
<property name="period">60</property>
<!-- roll every hour (60 minutes) -->
</configuration>
</export>VoltDB supports built-in connectors for five types of external targets: file, HTTP (including Hadoop), JDBC, Kafka, and Elasticsearch. Each export connector supports different properties specific to that type of target. Section 15.3, “VoltDB Export Connectors” describes the built-in export connectors and the required and optional properties for each.
Migration is a special case of export that synchronizes export with the deletion of data in database tables. When you migrate a record, VoltDB ensures the data is successfully transmitted to (and acknowledged by) the target before the data is deleted from the database. This way you can ensure the data is always available from one of the two systems — it cannot temporarily "disappear" during the move.
You define a VoltDB table as a source of migration using the MIGRATE TO TARGET clause, the same way you define an export source with the EXPORT TO TARGET clause. For example, the following CREATE TABLE statement defines the orders table as a source for migration to the oldorders target:
CREATE TABLE orders
MIGRATE TO TARGET oldorders
( {column-definition} [,...] );Migration uses the export subsystem to perform the interaction with the external data store. So you can use any of the supported connectors to configure the target of the migration; and you do so the exact same way you do for any other export target. The difference is that rather than exporting the data when it is inserted into the table, the data is exported when you initiate migration.
You trigger migration at run time using the MIGRATE SQL statement and a WHERE clause to identify the specific rows to move. For example, to migrate all of the orders for a specific customer, you could use the following MIGRATE statement:
MIGRATE FROM orders WHERE custmer_id = ? AND NOT MIGRATING;
Note the use of NOT MIGRATING. MIGRATING is a special function that identifies all rows that are currently being migrated; that is, where migration (and deletion) has not yet completed. Although not required — VoltDb will skip rows that are already migrating — adding AND NOT MIGRATING to a MIGRATE statement can improve performance by reducing the number of rows evaluated by the expression.
Once the rows are migrated and the external target acknowledges receipt, the rows are deleted from the database.
To further automate the migration of data to external targets, you can use the MIGRATE TO TARGET clause with USING
TTL. USING TTL automates the deletion of records based on a TTL value and a column (usually a TIMESTAMP) in the table. For
example, adding the clause USING TTL 12 HOURS ON COLUMN created to a table where the
created column defaults to NOW, means that records will be deleted from the table 12 hours after they
are inserted. By adding the MIGRATE TO TARGET clause, you can tell VoltDB to migrate the data to the specified target
before removing it when its TTL expiration is reached.
CREATE TABLE sessions MIGRATE TO TARGET sessionlog ( session_id BIGINT NOT NULL, created TIMESTAMP DEFAULT NOW [,...] ) USING TTL 12 HOURS ON COLUMN created;